
¿Qué es ChatGPT?
ChatGPT es una inteligencia artificial, basada en un modelo de procesamiento de lenguaje natural, que está entrenada para mantener conversaciones, de manera que solo tienes que hacerle preguntas de manera convencional y las entenderá, es decir, es un chat, como su propio nombre indica, capaz de mantener una conversación con el usuario. Por tanto, sus algoritmos deben primeramente entender que es lo que se les está preguntando y, posteriormente, ser capaces de dar una respuesta a la pregunta formulada.
Una vez que se crea un usuario (previa introducción de tus datos personales), se abre un chat en el que puedes pedirle que resuma artículos, desarrolle una narración o un texto dándole una serie de pautas más o menos precisas, que te explique un concepto complejo, que cree código informático, etc.
Como toda IA, se la debe entrenar para producir texto, usando técnicas de aprendizaje reforzado, es decir, los algoritmos requieren técnicas de aprendizaje para mejorar su precisión, es un modelo de aprendizaje conductual. El sistema no está entrenado con un conjunto de datos de muestra, lo que hace es aprender a través de mecanismos de prueba y error, es decir, cuantos más datos de entrada le faciliten los usuarios más datos tendrá para entrenar sus algoritmos. Por ello, hay que tener extrema precaución al facilitarse información sensible, compañías como Amazon ya han alertado a sus trabajadores sobre el uso de esta herramienta.
Eso sí, ChatGPT está programada para ser conversacional, no para ser veraz en sus respuestas y ahí reside parte de su peligro, en la coherencia de sus respuestas.
Sobre el tratamiento de datos personales por parte de ChatGPT (OpenAI)
Los términos y condiciones de ChatGPT establecen que “OpenAI le asigna todos sus derechos, títulos e intereses en y para la Salida. OpenAI puede usar el Contenido según sea necesario para proporcionar y mantener los Servicios, cumplir con la ley aplicable y hacer cumplir nuestras políticas. Usted es responsable del Contenido, incluso de asegurarse de que no infrinja ninguna ley aplicable o estos Términos.”
Por “contenido” debe entenderse los datos de entrada y de salida, es decir las preguntas y las respuestas, por lo que traslada toda la responsabilidad al usuario sobre el uso correcto de la información facilitada por el sistema.
“Para ayudar a OpenAI a proporcionar y mantener los Servicios, usted acepta e indica que podemos usar el Contenido para desarrollar y mejorar los Servicios.” Es decir, que toda la información facilitada al sistema podrá ser usada para entrenar a sus algoritmos.
Según indican “Eliminamos cualquier información de identificación personal de los datos que pretendemos utilizar para mejorar el rendimiento del modelo.” Es decir, dicen que los eliminan, supuestamente, para esa finalidad, pero ¿y para otras finalidades?
Si no quieres que tus datos de entrada se utilicen para entrenar el modelo, se debe enviar una solicitud por email, es decir, que hay un consentimiento predefinido al uso de los datos de entrada para esa finalidad por lo que, si no quieres que así sea se debe enviar una solicitud por lo que el consentimiento, de conformidad con lo establecido en el RGPD no sería libre, salvo que la base de legitimación para entrenar la IA sea otra, como el interés legítimo y se opte, por tanto, por un derecho de oposición.
La política de privacidad de OpenAI ya avisa que recopilan la información que se le proporciona, como los datos para crear cuenta y los de cualquier mensaje que se envíe, lo cual no concuerda con lo dicho sobre en T&C, y la combina con otra información de la que disponen, por ejemplo, a través de RRSS, además de recopilar la información sobre la navegación (IP, dispositivo, navegador, interacción de usuario, etc.) y cookies.
Hay que tener en cuenta que es perfectamente aplicable el RGPD teniendo en cuenta su ámbito de aplicación (art. 3):
“El presente Reglamento se aplica al tratamiento de datos personales de interesados que residan en la Unión por parte de un responsable o encargado no establecido en la Unión, cuando las actividades de tratamiento estén relacionadas con:
- la oferta de bienes o servicios a dichos interesados en la Unión, independientemente de si a estos se les requiere su pago, o
- el control de su comportamiento, en la medida en que este tenga lugar en la Unión.”
La empresa, OpenAI, está situada en California, pero le es aplicable el RGPD por lo anterior. Si hay uso directo por parte del usuario final no existirá transferencia internacional de datos, pero sí si el uso de la herramienta se produce por parte de un responsable del tratamiento que incorpora la herramienta a sus procesos y, consiguientemente será aplicable el Capítulo V RGPD.
Así utiliza nuestros datos ChatGPT según su política de privacidad:

La política de privacidad no especifica de donde provienen los datos de entrenamiento si bien es evidente que provienen de un “raspado” y extracción de datos de internet y RRSS, por lo que en cualquier caso habría que estar atento a las posibles consecuencias en materia de privacidad, pues los modelos de entrenamiento podrían contener conjuntos masivos de datos personales debiendo contar, en su caso, para su tratamiento, con una base de legitimación (art. 6.1 RGPD) al reutilizar los datos para una finalidad distinta de la principal, en el caso de la normativa sobre protección de datos, derivándose también implicaciones en materia de propiedad intelectual, en cuanto al uso de obras de terceros para el entrenamiento de la IA a través de la minería de texto y datos, de la que se hablará más adelante.
Teniendo en cuenta lo anterior queda expedita la vía de interponer reclamación ante la DPA competente, en virtud de los múltiples incumplimientos que se detectan.
Limitación al tratamiento de datos por parte de la DPA italiana.
Los usuarios italianos que se conecten a ChatGPT, desde la semana pasada, van a ver el siguiente mensaje:
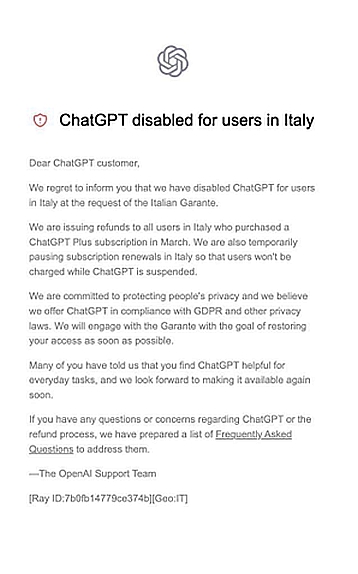
Lo anterior es debido a la decisión de la Autoridad de Control italiana en materia de protección de datos (Garante per la Protezione Dei Dati Personali) que ordenó, el pasado 31 de marzo, la limitación temporal inmediata al procesamiento de los datos personales de los usuarios italianos por parte de OpenAI e inició una investigación sobre la plataforma.
De hecho, y puede que la orden tenga que ver con ello, el pasado 20 de marzo una brecha de seguridad afectó a ChatGPT y se hicieron visibles datos personales de los usuarios en las sesiones de terceros.
La DPA italiana destaca en su comunicado que no se proporciona información a los usuarios cuyos datos son recopilados por OpenAI y, aparentemente, no parece haber una base legal que sustente la recopilación y el procesamiento masivos de datos personales para “entrenar” los algoritmos en los que se basa la plataforma.
Asimismo, la DPA italiana pone también el foco en la falta mecanismos de verificación de edad ya que el sistema expone a los niños a recibir respuestas que son absolutamente inapropiadas para su edad, a pesar de que el servicio supuestamente está dirigido a usuarios mayores de 13 años de acuerdo con los términos y condiciones de OpenAI.
La DPA le concede a OpenAI un plazo de 20 días para acreditar las medidas aplicadas para cumplir la orden, exponiéndose, en caso contrario, a una multa de hasta 20 millones de euros o el 4% del volumen de negocios anual total en todo el mundo.
¿Qué van a hacer las otras Autoridades de Control?
Según ha informado Reuters la DPA irlandesa y la francesa se han comunicado con la italiana para obtener más información acerca de la limitación impuesta por esta y a los efectos de coordinar posibles acciones sobre OpenAI. Alemania podría seguir el mismo camino que Italia.
La DPA sueca, de momento, no tiene previsto llevar a cabo ninguna acción sobre ChatGPT y la Agencia Española de protección de datos indicó que, por el momento no ha recibido ninguna reclamación contra ChatGPT si bien no descartaba iniciar una investigación de oficio en el futuro.

Gerard Espuga Torné
Abogado.
Saber más
