
I. ¿Qué y que no inteligencia artificial?
Este mes de diciembre se han publicado por parte del European Law Institute (ELI) las Guidelines on the Application of the Definition of an AI System in the AI Act: ELI Proposal for a Three-Factor Approach.
No fácil, en ocasiones, distinguir entre un Sistema de IA y otros sistemas. Así, el ELI establece tres factores a tener cuenta en relación con la definición de sistema de IA establecido por el artículo 3.1 del Reglamento de IA.
- Factor I: la cantidad de datos o conocimiento específico que se utilizó para el desarrollo.
- Factor II: Grado de know-how, entendido como la presencia de algoritmos de optimización, diferenciando los cálculos simples de los sistemas capaces de generar nuevo conocimiento sobre la resolución de un problema.
- Factor III: El grado de indeterminación de los resultados, en el sentido de realizar tareas que, si las realizara un humano, requerirían un juicio subjetivo o interpretación creativa.
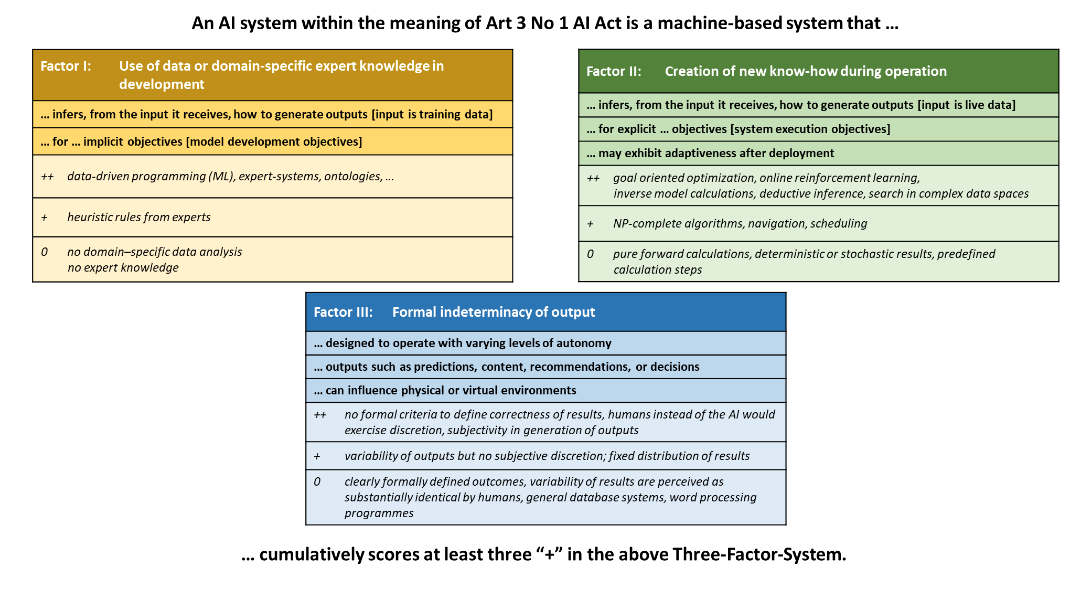
Así, para que in sistema pueda considerarse IA deben estar presentes, como mínimo, dos de los anteriores tres factores.
Además, debe distinguirse el “modelo de IA” del “sistema de IA”. El primero es el componente que hace funcionar el segundo. De conformidad con el art. 3.63 del Reglamento de IA, un “modelo de IA de uso general” es “un modelo de IA, también uno entrenado con un gran volumen de datos utilizando autosupervisión a gran escala, que presenta un grado considerable de generalidad y es capaz de realizar de manera competente una gran variedad de tareas distintas, independientemente de la manera en que el modelo se introduzca en el mercado, y que puede integrarse en diversos sistemas o aplicaciones posteriores, excepto los modelos de IA que se utilizan para actividades de investigación, desarrollo o creación de prototipos antes de su introducción en el mercado”
Teniendo claro lo anterior, el presente documento se centrará en examinar la Opinión 28/2024, del EDPB sobre el tratamiento de datos personales en el contexto del desarrollo y uso de modelos de inteligencia artificial.
II.- Tratamiento de datos en modelos de inteligencia artificial. El precedente de la DPA de Hamburgo.
A finales de julio, la DPA de Hamburgo publicaba un discussion paper en el que, someramente, indicaba que, efectivamente, no es lo mismo tratar datos personales en un modelo de IA (GPT) que en un sistema de IA (Copilot o ChatGPT).
Asimismo, indicaba que:
- El simple almacenamiento de un LLM no supone un tratamiento de datos personales ya que los mismos no se contienen en el modelo. Sí existe tratamiento, en cambio, cuando se entrena el modelo.
- Los derechos de los interesados no pueden ejercitarse ante el modelo sino ante el sistema que lo utiliza.
- Los LLM no almacenan textos en formato original, sino que lo hacen mediante tokens (dividiendo el texto de entrada en varias partes). Para dar una salida transforma esos tokens (según las correlaciones) en el formato solicitado, texto, por ejemplo.
- Los LLM no almacenan los textos utilizados para el entrenamiento en su forma original, sino que los procesan de tal manera que el conjunto de datos de entrenamiento nunca puede reconstruirse completamente a partir del modelo.
- La DPA de Hamburgo concluye que un LLM no almacena datos personales ya que los tokens que procesa el LLM, como fragmentos de lenguaje, carecen de contenido de información individual y no permiten identificar a una PF. Incluso si, a través de ataques dirigidos al LLM se extrajeran datos personales ello supondría un «esfuerzo desproporcionado» para identificar a una PF por parte del responsable o de terceros.
- Asunto distinto es el tratamiento de datos de un responsable que implementa el modelo a través de un sistema de IA que estará sujeto a las obligaciones del RGPD y a verificar la adecuación y seguridad del modelo. Es el desarrollador del modelo el que debe responder si se producen incumplimientos en fase de entrenamiento.
III.- La opinión 28/2024 del EDPB sobre aspectos relacionados con el tratamiento de datos personales en el contexto de los modelos de inteligencia artificial.
A petición de la DPA irlandesa, el EDPB emitió, el pasado 17 de diciembre, su opinión sobre el desarrollo y uso de modelos de inteligencia artificial. La solicitud alcanza todo el ciclo de vida de los modelos de IA (creación, desarrollo, entrenamiento, actualización, ajuste y/o reentrenamiento).
Cabe recordar que los modelos de inteligencia artificial son componentes esenciales de los sistemas de IA, si bien no constituyen sistemas por sí mismos. La opinión solo cubre los modelos de IA que son el resultado de un entrenamiento de dichos modelos con datos personales y realiza recomendaciones dirigidas a las DPA a los efectos de evaluar dichos modelos respecto del tratamiento de datos personales.
a) ¿Un modelo de IA previamente entrenado con datos personales es anónimo o no?
La finalidad última de un modelo de IA es hacer predicciones, inferencias, normalmente sobre personas distintas de aquellas cuyos datos se han utilizado para el entrenamiento, pero ello no siempre es así. En ese caso, dichos modelos incluirán datos personales y, por tanto, no serán anónimos, por ejemplo, un modelo generativo ajustado a partir de las grabaciones de voz de una persona para imitar su voz.
La opinión del EDPB, no obstante, se centra en los primeros modelos. Así, la información del conjunto de datos de entrenamiento, incluidos los datos personales, puede seguir “absorbida” en los parámetros del modelo, es decir, representada mediante tokens o matemáticamente, vectorizada.
A estos efectos, siempre que la información relativa a personas identificadas o identificables cuyos datos personales se hayan utilizado para entrenar el modelo pueda obtenerse de un modelo de IA con los medios que son razonablemente probables que se utilicen, puede concluirse que dicho modelo no es anónimo. El CEPD considera que los modelos de inteligencia artificial entrenados con datos personales no pueden considerarse anónimos en todos los casos. En cambio, la determinación de si un modelo de IA es anónimo debe evaluarse, en función de criterios específicos, caso por caso, debiendo valorar las posibilidades de extracción de datos personales del modelo o su obtención accidental durante la interacción con el mismo.
b) ¿Cuándo un modelo de IA puede considerarse anónimo?
Se puede hablar de información personal incluso cuando esta está organizada o codificada técnicamente para que solamente sea legible por máquinas. En estos casos, se puede utilizar software para identificar, reconocer y extraer fácilmente datos específicos.
Puede ser posible inferir datos personales mediante relaciones probabilísticas entre los datos contenidos, por lo que para que un modelo puede considerarse anónimo se debe comprobar si ha realizado pruebas suficientes de que, con medios razonables, los datos personales relacionados con los datos de entrenamiento no pueden extraerse del modelo y si cualquier resultado producido al consultar el modelo no se relaciona con los interesados cuyos datos personales se utilizaron para entrenar el modelo. Para ello, deben tenerse en cuenta algunos elementos básicos:
- Evaluación de los mecanismos de anonimización y, en su caso, del riesgo de identificación tanto por el responsable como por parte de terceros (mal o bienintencionados), que debe ser “insignificante” para considerarse anónimo.
- Lo anterior, teniendo en cuenta todos los medios que es razonablemente probable que utilice el responsable del tratamiento o terceros para identificar a personas físicas, si bien la STJUE en el asunto Breyer ya dejó en claro que solo son relevantes los medios legales de (re)identificación.
c) Evaluación del riesgo residual de identificación.
La evaluación sobre si un modelo puede considerarse anónimo puede diferir de un modelo a otro en función, también, de si el modelo es público o privado, las medidas que hayan adoptado los responsables y la resistencia a los ataques. El EDPB ofrece una lista no exhaustiva sobre elementos a tener en cuenta, por ejemplo:
El diseño del modelo: analizando las fuentes utilizadas para entrenar el modelo, las medidas adoptadas para evitar o limitar la recopilación de datos personales y la exclusión de determinadas fuentes.
- Minimización de datos: uso de datos anónimos o seudonimizados, en su caso, motivación para no hacerlo, técnicas de minimización y de eliminación de datos irrelevantes y de la identificabilidad en general con especial atención a las técnicas empleadas.
- Medidas para evitar la extracción de datos: reducción de la probabilidad de obtener datos personales relacionados con el entrenamiento a partir de los inputs.
- Valoración de si se han realizado auditorías que incluyan la evaluación de las medidas elegidas para limitar la probabilidad de identificación y revisiones de código.
- Análisis de las pruebas efectuadas al modelo, en particular, las pruebas parar evitar ataques ya conocidos, entre otros, inferencia de atributos, exfiltración, “regurgitación” de los datos de entrenamiento, reconstrucción o inversión.
- Documentar las operaciones de tratamiento teniendo en cuenta las EIPDs, las medidas técnicas y organizativas adoptadas en fase de diseño y durante el ciclo de vida y de la información facilitada a otros responsables del despliegue o interesados.
d) Interés legítimo para el entrenamiento del modelo.
Más allá de los principios generales (lealtad, transparencia, limitación de la finalidad, minimización, etc.) el EDPB analiza de manera específica los tres pasos necesarios para evaluar el interés legítimo en el desarrollo y despliegue de modelos de inteligencia artificial.
Como siempre, la evaluación del interés debe realizarse caso por caso (contextualmente) pero siempre debe ser un interés lícito, claro, preciso, real y presente, por ejemplo, como ya indicó la CNIL, un interés puede ser legítimo si sirve para desarrollar el servicio de un agente conversacional para ayudar a los usuarios, para desarrollar un sistema de IA para detectar contenido o comportamiento fraudulento o mejorar la detección de amenazas en un sistema de información.
Respecto a la “necesidad” del tratamiento, debe evaluarse el volumen de datos personales tratados para el desarrollo del modelo y si es posible alcanzar la misma finalidad con un tratamiento menor de datos personales. La implementación de medidas técnicas también puede ayudar a superar la prueba de necesidad, aun sin alcanzarse la anonimización, pero reduciendo la facilidad de identificar a los interesados.
En cuanto a la ponderación de los intereses en juego, los intereses de las personas físicas pueden incluir, entre otros, intereses en conservar el control sobre los propios datos personales, intereses financieros, beneficios personales (por ejemplo, cuando un modelo de IA se utiliza para mejorar la accesibilidad a determinados servicios) o intereses socioeconómicos (por ejemplo, cuando un modelo de IA permite el acceso a una mejor atención sanitaria o facilita el ejercicio de un derecho fundamental como el acceso a la educación).
Evidentemente, durante la fase de desarrollo pueden plantearse distintos riesgos para los derechos de los interesados, como la inferencia de datos o la posibilidad de identificación (ya sea bien o malintencionadamente), la sensación de vigilancia permanente debido a la recopilación masiva de datos que, a su vez, puede suponer riesgos para la libertad de expresión o cuando se toman decisiones automatizadas que pueden suponer discriminación sobre los interesados.
Estos riesgos, no solo se presentan en fase de desarrollo sino también en fase de implementación o uso del modelo, por lo que deben ser evaluados teniendo en cuenta los métodos de tratamiento, su combinación con otros datasets, la escala del tratamiento, la situación del interesado o la relación con el interesado. Por ejemplo, el web scraping puede tener graves consecuencias sobre los interesados si no se toman las medidas suficientes.
Las expectativas de los interesados (factor clave a mi juicio para la prueba de equilibrio), como no puede ser de otra manera, deben ser tenidas en cuenta en la pondenración del interés legítimo, para lo cual es fundamental facilitar la información oportuna si bien la mera información del art. 13 RGPD no es necesariamente suficiente para que los interesados puedan esperar razonablemente un tratamiento, por tanto, no lo es la mera inclusión de la información en la política de privacidad del responsable.
Debo decir que mantengo algunas dudas sobre si el paso del tiempo puede modificar las expectativas legítimas de los interesados en el sentido de que lo que en un momento dado puedo no esperarse, puede esperarse en otro, esto es, las expectativas de los interesados pueden ser unas en un momento (quizá hoy en día podemos razonablemente no esperar que nuestros datos públicos en internet sean utilizados para entrenar sistemas de IA) pero cambiar a corto plazo.
No podemos decir que las expectativas de los interesados sean las mismas si los interesados facilitan directamente los datos a los interesados que si no lo hacen o si existe o no un vínculo del interesado con el responsable, las expectativas de aquel pueden ser distintas.
El EDPB propone distintas medidas para mitigar la prevalencia de los derechos y libertades de los interesados, cosa que parece un tanto incongruente, pues si los mismos prevalecen, prevalecen, no debería intentarse eludir dicha prevalencia. En cualquier caso, el EDPB recomienda medidas para evitar la reidentificación de los interesados, utilizar datos sintéticos o falsos, facilitar un opt-out a los interesados desde el principio o algunas medidas específicas para web scraping como la exclusión de determinados contenidos, categorías de datos o sitios web e incluso listas de exclusión voluntaria.
Algunas de las medidas anteriores también pueden implementarse en fase de uso del modelo, pero además también pueden implementarse otras como aquellas que eviten la “regurgitación” o generación de datos personales o la reutilización de contenidos (con marcas de agua).
IV.- Licitud del uso posterior de un modelo desarrollado mediante un tratamiento de datos ilícito.
Como viene siendo costumbre, el “dependerá del caso concreto” vuelve a aparecer en la respuesta a si la ilicitud del tratamiento en fase de desarrollo puede afectar a la fase de uso.
Por ejemplo, en relación con la base jurídica del interés legítimo, cuando el tratamiento posterior se basa también en un interés legítimo del mismo responsable, el hecho de que el tratamiento inicial fuera ilícito debe tenerse en cuenta en la evaluación del interés posterior. En estos casos, la ilicitud del tratamiento en la fase de desarrollo puede afectar a la licitud del tratamiento posterior.
Un caso distinto es aquel en que el responsable trata datos ilícitamente en fase de desarrollo, posteriormente anonimiza el modelo antes de que él mismo o un tercero lo implemente, en ese caso, la ilicitud del tratamiento inicial no debería afectar al funcionamiento posterior del modelo, sin perjuicio del incumplimiento previo del RGPD por parte del desarrollador.
